

ETL
ETL是extract,transfrom,load三个单词的首字母拼写,它是从一个系统将数据迁移到另一个系统的的过程。
它主要经历三个步骤。
1.数据提取-从类似或者不同的源中检索数据来进行进一步的数据处理和数据存储的过程。
2.数据转换-在数据处理过程中,将清除数据,并修改或删除不正确或不正确的记录。
3.数据加载-将处理后的数据加载到目标系统中,例如数据仓库或NoSQL或RDBMS。

Spark
Apache Spark是一个支持多编程语言API的的开源数据计算系统。它是专为大规模数据处理而设计的快速通用的计算引擎,因为数据处理是在内存中完成的,因此它比MapReduce快上100倍。
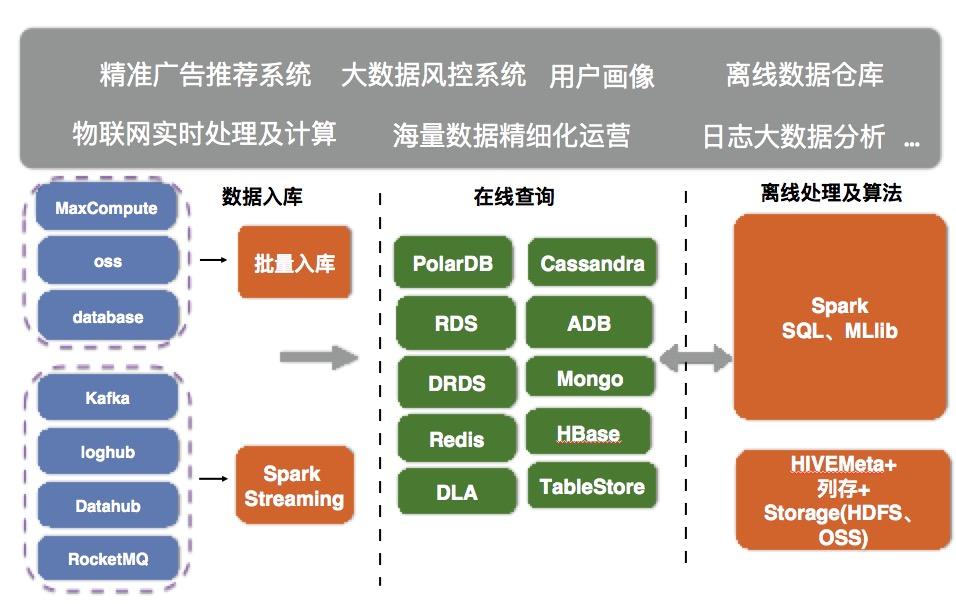
Spark配备了一组丰富的数据处理工具库,包括库Spark Sql为SQL和结构化数据的处理,MLlib用于机器学习,GraphX用于图形处理,Spark Stream 用于处理数据流。
Spark可以在本地计算机上运行,也可以扩展到数百个节点的群集。
Spark使用流程
创建SparkSession。
它是一个驱动程序进程,它维护有关Spark应用程序的所有相关信息,并且它还负责在所有执行程序之间分发和调度应用程序。
def initialize_spark ():
spark = SparkSession.builder
.master("local[*]")
.appName("simple etl job")
.getOrCreate()
return spark使用DataFrameReader来完成CSV的读取。
定义手动模式,可以方便提高我们的读取速度。
def load_df_with_schema(spark):
schema = StructType([
StructField("dateCrawled", TimestampType(), True),
StructField("name", StringType(), True),
StructField("offerType", StringType(), True),
StructField("price", LongType(), True),
StructField("abtest", StringType(), True),
StructField("dateCreated", DateType(), True),
StructField("nrOfPictures", ShortType(), True),
StructField("lastSeen", TimestampType(), True)
])
df = spark.read
.format("csv")
.schema(schema)
.option("header", "true")
.load(environ["HOME"] + "/data/autos.csv")
print("Data loaded into PySpark", "\n")
return df 数据转换,因为几乎所有提取的数据都会有某些字段的缺失或者不正确,我们需要对数据进行二次处理,就是过滤或者去除无用的数据列。
数据加载,数据转换之后,我们需要将数据进行保存,这里我们使用mysql数据库进行保存。
1.使用pip安装MySQL Connector Python。
2.使用MySQL Connector Python的mysql.connector.connect()方法和必需的参数来连接MySQL。
3.使用connect()方法返回的连接对象创建一个游标对象以执行数据库操作。
4. cursor.execute()用于从Python执行SQL查询。
5.工作完成后,使用cursor.close()关闭Cursor对象,并使用connection.close()关闭MySQL数据库连接。
6.如果在此过程中可能发生任何异常,则捕获异常。
创建表后,现在可以使用我们的数据集填充它了。我们可以通过将数据作为元组列表(每个记录为一个元组)提供给INSERT语句来插入数据:

总结
在大数据处理方面,python提供了非常多好用的包,其中pyspark就是处理spark非常好用的工具,使用它,我们可以轻松构建出我们的大数据平台。

 QQ客服专员
QQ客服专员 电话客服专员
电话客服专员